時間過很快,一下子就到第六天了!這2天看到有人願意訂閱這系列文章讓我很是感動!
希望在這跌跌撞撞的分享中能多少幫助大家!
好了,回顧前五天我們所做的,已經能夠順利把LINE的訊息推播到手機了!接下來我們要做的就是去嘗試寫出一隻簡易爬蟲,把我們想要接收的資訊爬下來再推送到手機上,最後再設定個排程我們的小目標就達成了!
很明顯的可能會有快20天的文章不知道要幹嘛,歡迎大家提提想法看想做些什麼!
回到今天的重點,爬蟲!
什麼是爬蟲咧?其實我也沒寫過欸,所以我們一起來估狗看看吧! 維基
快速了解吸收一下,簡單來說就是把網頁(html)給摘下來,接著透過程式去篩選出對我來說有意義的資訊!
當然還有更厲害更高竿的做法就是在觀察當前頁面的資訊後給予適當的header或是先打A拿到資訊後再打B的各種爬蟲!很深奧吧!
這邊有看到也是同樣參加鐵人賽的選手文章,我覺得內容很紮實詳細,大家可以去看看~ 連結
那所以說這次的需求我們是要做很麻煩的爬蟲嗎?不!當然是選最簡單的開始啊!
如果以圖片來說的話!
從右至左都是鳴人,但一個是還在拿油漆畫三代目雕像的屁孩!一個是可以屌打夜輝的大神!
學習是急不來的!用心體悟心靈祥和比較重要! /目\
首先第一步,要站在巨人的肩膀上!所以我們來找套件吧!
composer require guzzlehttp/guzzle
composer require symfony/dom-crawler
guzzlehttp/guzzle太大聲(?)就不多說了,
那為什麼爬蟲會選symfony/dom-crawler咧?其實當下也沒特別多想,只是看它的測試好像用起來挺方便的,所以就是它了!
而且而且!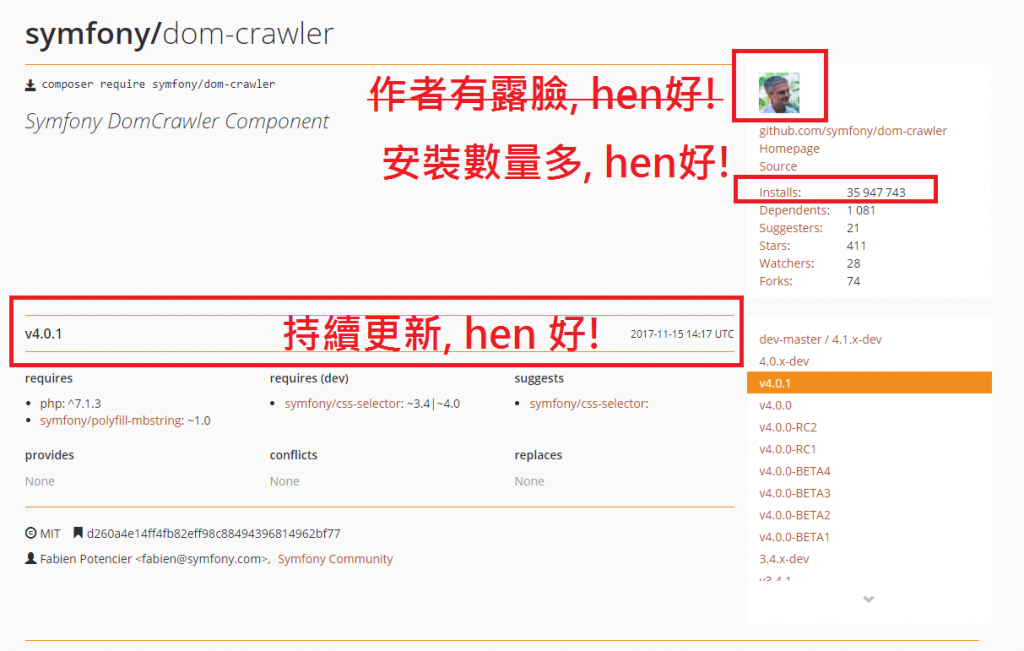
所以就是它了別怕!
用起來也一點都不麻煩,
我們可以很直覺的就寫出來這些!
CrawlerService.php
<?php
namespace App\Services;
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
class CrawlerService
{
/** @var Client */
private $client;
public function __construct()
{
$this->client = app(Client::class);
}
/**
* @param string $path
* @return Crawler
*/
public function getOriginalData(string $path): Crawler
{
$content = $this->client->get($path)->getBody()->getContents();
$crawler = new Crawler();
$crawler->addHtmlContent($content);
return $crawler;
}
}
CrawlerServiceTest.php
<?php
namespace Tests\Feature\Services;
use App\Services\CrawlerService;
use Tests\TestCase;
class CrawlerServiceTest extends TestCase
{
/** @var CrawlerService */
private $crawlerService;
public function setUp()
{
parent::setUp(); // TODO: Change the autogenerated stub
$this->crawlerService = app(CrawlerService::class);
}
public function tearDown()
{
parent::tearDown(); // TODO: Change the autogenerated stub
}
public function testGetOriginalData()
{
$crawler = $this->crawlerService->getOriginalData('https://ani.gamer.com.tw/');
$this->assertNotEmpty($crawler->html());
}
}
但接下來就要看範例(測試)和文件了! 文件
呃...雖然前幾天假日有寫了一些,但暫時還想不到該怎麼解釋類似以下的東西。
$target = $crawler->filterXPath('//div[contains(@class, "newanime")]')
大家可以先看看這個文件 中文範例
今天時間差不多啦!剩下的我們明天完成!
(趕快去找相關資料來補腦!)


